Help Build NODE-ECON
Originally published September 22, 2017
Origins
Around 2000 or 2001, I started working with Max/MSP and Pure Data for sound synthesis. For a technically-minded musician, the interface and underlying concepts are intuitive and allow for rapid development of sound-making objects without the need for writing tons of code. At the same time, these objects are highly customizable, so if I ever needed to alter the tools on a more fundamental level, those options were also available.
Around the same time, I started my formal studies in economics while working as a market analyst. Spending so much time on collecting, cleaning up, and managing data led me to think about better ways to do all of this on a shoestring budget, and without having to double major in computer science. The knowledge management systems our company was considering were six-figure propositions at the time, and we simply didn’t have the resources for sustained in-house software development, so we kept using what we had, which was Excel and, eventually, a SQL back end that required constant attention for only modest benefits.
The graphical object and flow model
I started toying around with a Max/MSP-like interface for the work I was doing, with modules for cleaning up and extracting data, running different kinds of analysis, and feeding data to templates that were built for specific purposes, such as PDF/print, merging into other documents, and data feeds that could be repurposed at the client end.
I learned a little R and Matlab and a modest amount of Python, but the data management aspects of all those tools never really stuck with me. I’m an out-of-sight, out-of-mind kind of person; all of that command line stuff has its place, but I never took to it as a way of actually working with my data.
Whatever the case, without any realistic way of making any change happen, this idea remained in limbo for much of the past decade.
Then I saw NODE-RED
If you’ve read this far, I presume you know about NODE-RED. If you don’t, you can find what you need here.
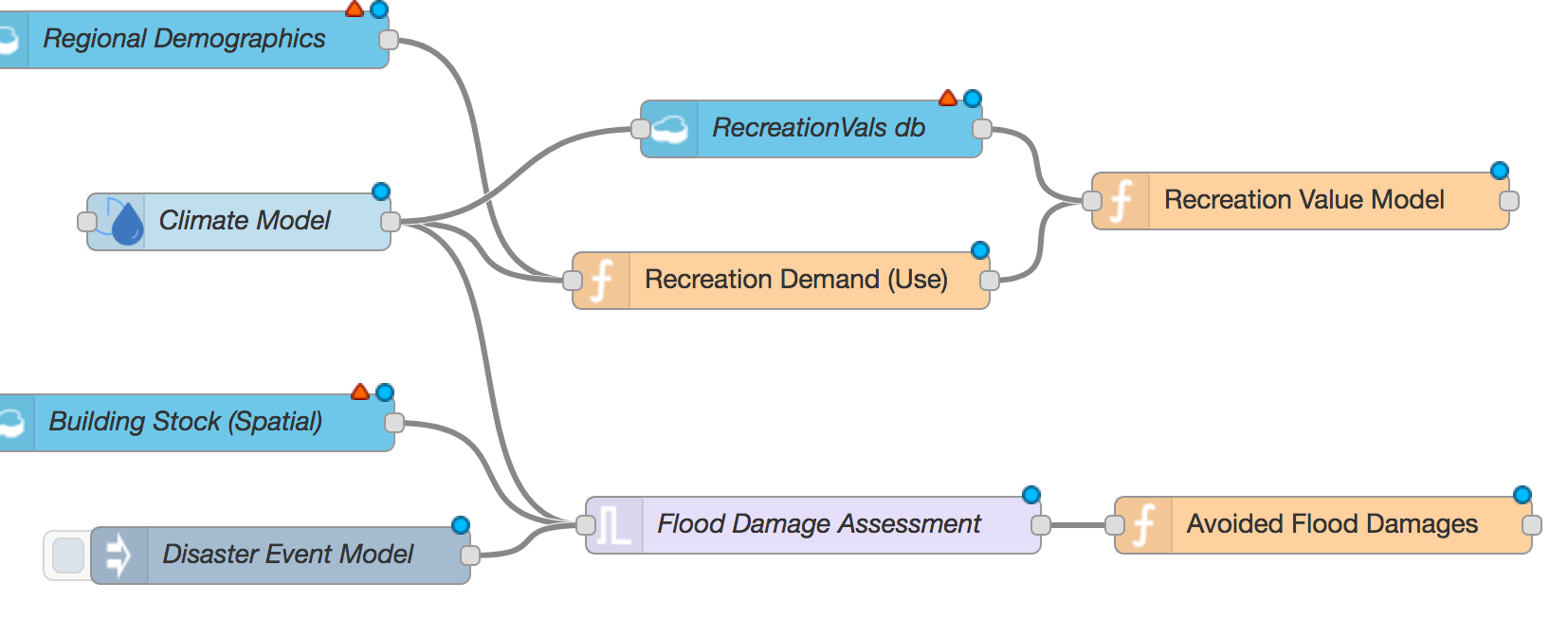
That's it. That’s the interface I was looking for. Some of the most common NODE-RED use cases are for IoT applications, but I think there’s a ton of potential for adapting the concepts and toolsets for use in economic analysis.
The goal is to create modules that just work together without a whole lot of tinkering. This requires some thinking about how data go into and out of individual modules, and quality control, and a whole lot of other considerations. Think about it for a moment. Would you use a tool that you can build that handles things like:
- Data ingestion from disparate sources: APIs, web scraping, CSVs, legacy systems, emails, hand-scrawled notes
- Unit conversions and other transformations
- More complex activities, like agent-based models, market simulations, bio-geo-economic models
- Summing and weighting of different models into one output
Yes, I know all this stuff already exists. But I envision more of an intermediate interface, somewhere between the notebook model and expensive tools like Stella and Simulink, based on open development principles.
Use it. Modify it. Contribute to it.
What we could really use is your help in building this idea into a living, breathing system, for use by practitioners in all of the branches of econ and decision science, from applied to theoretical, from micro to macro, from environmental and natural resources to labor and technology.
Contact me at kyle@integrativeecon.com if you’d like to get involved!